Overview
Meeting transcripts are full of signal buried in noise. Decisions get made, deferred, revised, and sometimes walked back, all within the same conversation. Extracting that signal automatically and routing it into a CRM without human review is a problem that breaks simple prompt-based approaches. A model that acts on everything creates bad data. A model that flags everything defeats the purpose.
This pipeline was built to process meeting transcripts for a financial advisory context. The brief: process four meeting transcripts, extract structured CRM updates and action items, and produce outputs ready to pipe into downstream systems. The constraint that shaped the entire architecture was confidence, because the system needed to know not just what to extract, but whether to act on it.
The Problem
A financial advisory firm generates dozens of meeting transcripts a day. Each one contains a mix of confirmed decisions, tentative ideas, deferred actions, and conversational noise. A CRM update applied from the wrong category corrupts the record. A flagged item that should have been auto-applied creates unnecessary review overhead.
The naive approach of sending the transcript, asking for a summary, and parsing the output fails in production because the model has no framework for distinguishing between a client who says "yes, let's do it" and one who says "let me think about that." Both are affirmative in tone. Only one should trigger an update.
The four test transcripts were each designed around a specific edge case:
- Transcript A covers clean confirmation, where the client gives clear verbal agreement on a specific action.
- Transcript B covers a deferred decision, where the client's intent is clear but they explicitly postpone action: "don't do anything yet."
- Transcript C covers a multi-party meeting, where two decision-makers reach a compromise after initial disagreement. The final position is what matters, not the opening positions.
- Transcript D covers off-topic noise, where a casual joke about market conditions sits alongside real action items. The system needs to ignore one and capture the other.
Each edge case is a real failure mode in production. The taxonomy was built to handle all four.
Architecture
Rather than writing a long instruction prompt telling the model how to behave, the pipeline uses a context engineering approach: five layers of structured reference material that the model reasons against.
Layer 1: System Layer
Defines the model's role and domain. Short, declarative, and with no ambiguity about what the model is doing or who it is working for.
Layer 2: Schema Layer
TypeScript types for every output field, injected into the prompt as annotated structure. The model knows the exact shape of what it needs to produce before it reads a single word of transcript. Field-level annotations explain intent, not just type.
Layer 3: Confidence Taxonomy
The core reasoning document. Three tiers with real phrase examples extracted from the test transcripts. The model classifies every extracted item against this reference rather than making a judgment call in isolation.
Layer 4: Meeting Metadata
Participant roles, decision-maker flags, and meeting structure. Transcript C required special handling because two decision-makers present means both must confirm before an update is marked HIGH confidence. This logic is injected as metadata rather than baked into the prompt.
Layer 5: Transcript Layer
The raw meeting content, processed last. By the time the model reaches the transcript, it has a role, a schema, a classification reference, and meeting context. It is reasoning against a complete system rather than an open-ended instruction.
This layering produces consistent results because every decision the model makes is traceable to a specific layer of context. Debugging a misclassification means identifying which layer failed, not re-reading a monolithic prompt.
The Confidence Taxonomy
The taxonomy is the design decision the entire pipeline depends on.
HIGH confidence: auto-apply
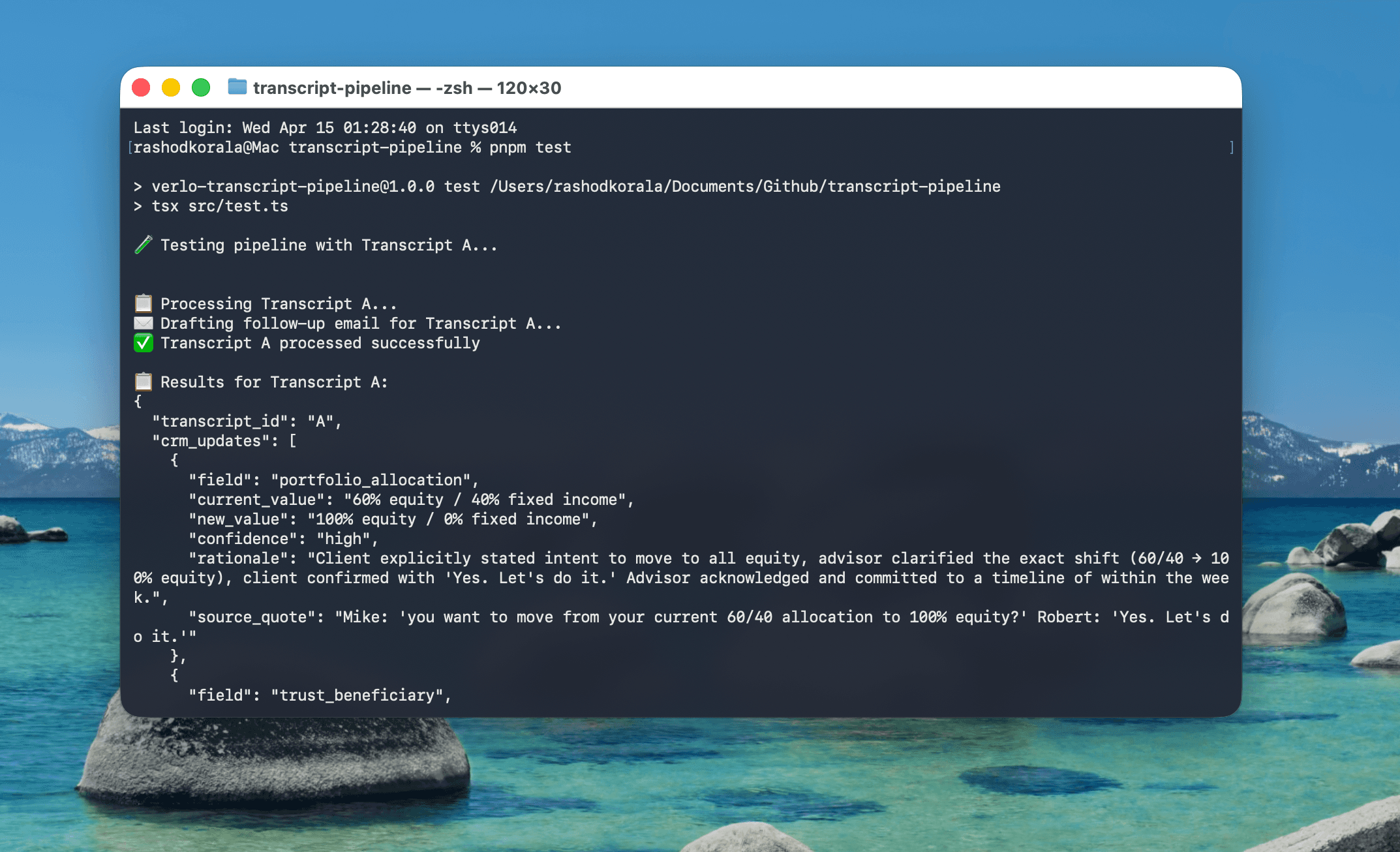
The client gives clear verbal confirmation and the advisor acknowledges the next step. Both sides close the loop. Examples from the transcripts: "Yes, let's do it," "Got it, I'll action that this week," a specific dollar value stated with agreement on both sides. These updates go directly to the CRM.
MEDIUM confidence: extract and flag for completion
The client's intent is clear but the action requires follow-up work before it can be applied. Examples: "I'll model that out," "Can you figure out what that looks like?" The decision is real but incomplete. The item is extracted with a flag noting what is missing.
LOW confidence: flag for human review and do not auto-apply
The client is thinking out loud, explicitly deferring, or the statement is ambiguous in context. Examples: "Don't do anything yet," "Maybe," "I don't know, what do you think?" These are surfaced for a human to review. Nothing is written to the CRM.
The critical design choice is that thresholds are defined by concrete phrase patterns rather than subjective rules. "The client seemed uncertain" is not an auditable classification. "The client used a deferral phrase matching the LOW tier examples" is. At scale, auditable logic is the only kind that holds.
Build
Pipeline Execution
The pipeline runs sequentially across all four transcripts. Each transcript is processed in a single API call with the full five-layer context injected. Temperature is set to zero for deterministic output, because this is extraction rather than generation.
Output per transcript:
- Structured JSON containing CRM field updates, action items, confidence classifications, and flagged items
- Plain-text follow-up email draft where the transcript contains a confirmed next communication
- Console summary for pipeline verification
Why Single Prompt Over a Chain
A multi-step chain that extracts first, classifies second, and formats third adds latency and introduces error propagation between steps. A misclassification in step two corrupts the format in step three. The five-layer context approach front-loads all the reasoning material into a single call, producing a complete structured output in one pass. For this scope and these transcripts, that is the cleaner architecture.
Schema Validation
Outputs are validated against Zod schemas before writing to file. If the model returns a response that does not conform to the expected shape, the pipeline catches the error, logs it, and retries with an explicit correction prompt. In practice, the structured context and zero temperature produce conformant output on first attempt consistently.
Scaling to Production
The pipeline was built for four transcripts. The architecture was designed for 1,000 per day.
Prompt caching: The system layer, schema layer, and confidence taxonomy are identical across every transcript. Anthropic's prompt caching means these layers are processed once and cached, reducing per-call cost significantly at volume.
Async batch processing: Sequential processing is appropriate for a demonstration. Production would run concurrent requests with rate limit management, reducing total pipeline runtime from linear to near-constant for batches within the API throughput ceiling.
Structured output mode: The current implementation parses JSON from the model's text response. Production would use Anthropic's tool use API to enforce schema compliance at the API level, eliminating the need for retry logic on malformed output.
Schema drift handling: As CRM fields evolve, the schema layer is the single point of change. Every downstream extraction adjusts automatically because the model reasons against the injected schema rather than a hardcoded field list.
Outcome
Every transcript was processed correctly, including the deferred decision in Transcript B (correctly classified LOW, not applied), the multi-party compromise in Transcript C (final position captured, opening positions ignored), and the off-topic noise in Transcript D (ignored, with real action items extracted).
The result is a demonstration of how to approach AI-powered extraction at production quality. The confidence taxonomy, the layered context architecture, and the scaling considerations go beyond the immediate brief because they are what the problem actually needs.
Reflection
The core question was what "working" means when the input is ambiguous by nature.
A pipeline that extracts everything and lets a human sort it out defers the problem. A pipeline that applies everything and trusts the model's judgment creates a data integrity risk. Working means knowing the difference, and having a system that makes that distinction consistently and auditably.
The confidence taxonomy is the answer to that question. Everything else in the pipeline is infrastructure around it.
Tools & tech stack